 Jose Ramon Palanco
Jose Ramon Palanco 
Sometimes we need to process tons of data, but scaling application is not easy, above all in python. That’s why I started researching about real-time data processing and I found out Apache Storm. Apache Storm is a technology released as open source software by Twitter for processing real-time data. This is the way the can provide for example the Trending Topics.
Wikipedia: Apache Storm is a distributed stream processing computation framework written predominantly in the Clojure programming language
Basically, with storm, you can process, manipulate and transform streams of tuples of data. There are 3 important concepts in storm.
Spouts: these are the source of the data. In general the spouts will retrieve the data from a queuing broker like Apache Kafka or RabbitMQ, but actually can use any source, for example, Twitter API.
Bolts: these consume inputs and produce outputs. Bolts can receive the input from spouts but also from other inputs. The logic goes in the bolt, so we can filter, join, aggregate, … the data and also store the result.
Topology: this defines how the spots and bolts work, so it is possible to describe how a spout retrieve some data and sent it a bolt which will send to another one and so on. Topologies run indefinitely when deployed.
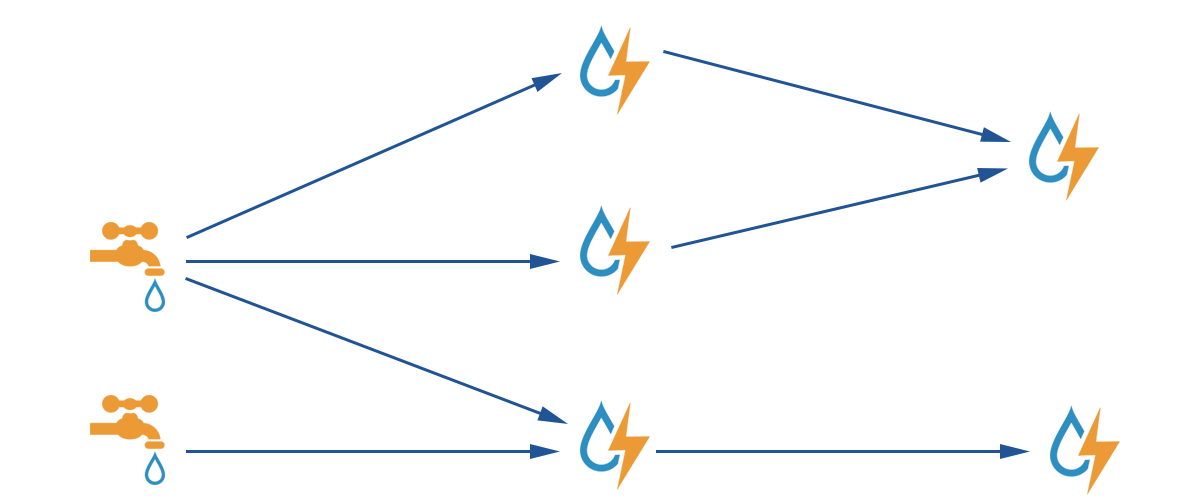
Figure 1: Example of topology
Once we have our topology, we need to deploy it, for that we will need a storm cluster. Storm clusters are composed of different components:
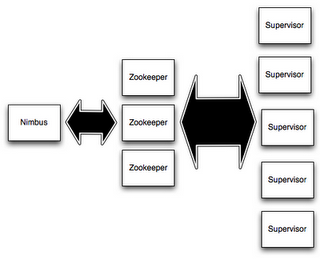
Figure 2: Apache Storm topology
- Nimbus is the daemon responsible for distributing code around the cluster, assigning tasks to machines, and monitoring for failures.
- Supervisor listens constantly for work assigned by nimbus.
- Zookeeper is a cluster by itself. It provides synchronization of data across the nodes. Nimbus and Supervisor are stateless so all state is kept in Zookeeper.
We can find also another interesting component: ui. The ui is a basic web application to display all the cluster details.
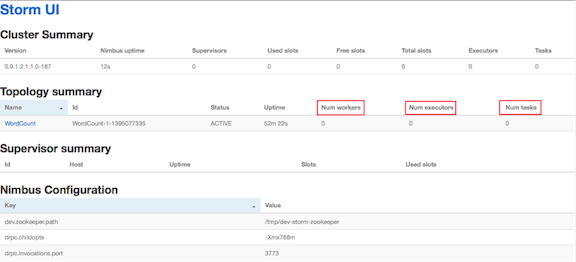
Figure 3: Apache Storm UI
![]()
Apache Storm supports Java and Python as languages for code distribution and execution, however, I found a library which makes the python integration pretty easy: streamparse.
Let’s see a project example, very basic, for counting words. This example is included in streamparse by default. This is the spout:
from itertools import cycle
from streamparse import Spout
class WordSpout(Spout):
outputs = ['word']
def initialize(self, stormconf, context):
self.words = cycle(['dog', 'cat', 'zebra', 'elephant'])
def next_tuple(self):
word = next(self.words)
self.emit([word])
In this example the spout is not retrieving the data from anywhere, it just define it at the initialize() method. This method should be used to initialize all the variables and retrieve the data or prepare the data to get retrieved. We will need to implement also a next_tuple() method witch will get the next piece of data and will convert it in a tuple that we want to emit to the bolt. The next_tuple() object will be continuously invoked, that’s why we need to initialize the variables before.
This is the bolt:
import os
from collections import Counter
from streamparse import Bolt
class WordCountBolt(Bolt):
outputs = ['word', 'count']
def initialize(self, conf, ctx):
self.counter = Counter()
self.pid = os.getpid()
self.total = 0
def _increment(self, word, inc_by):
self.counter[word] += inc_by
self.total += inc_by
def process(self, tup):
word = tup.values[0]
self._increment(word, 10 if word == "dog" else 1)
if self.total % 1000 == 0:
self.logger.info("counted [{:,}] words [pid={}]".format(self.total,
self.pid))
self.emit([word, self.counter[word]])
We have also an initialize() method. But the most import method is process(), which will receive a tuple from the spout and will perform the logic. It will also emit a tuple result of the logic.
The topology:
from streamparse import Grouping, Topology
from bolts.wordcount import WordCountBolt
from spouts.words import WordSpout
class WordCount(Topology):
word_spout = WordSpout.spec()
count_bolt = WordCountBolt.spec(inputs={word_spout: Grouping.fields('word')},
par=2)
As you can see this topology called WordCount, describes how the word_spout will be the input to the bolt. By default, the tuple can be sent to any executor, but we can change this behavior using ‘Grouping’. In this example, we are sending all the tuple with the same field ‘word’ to the same executor always, so it will be able to count all the words that are the same. It also will use 2 parallel instances of this bolt across all the cluster.
[bctt tweet=”Real-time processing with Python #python #distributed” username=”jpalanco”]
I’ve created a docker composer infrastructure, so it will be very easy to make it run. You can download it from: https://github.com/jpalanco/streamparse-wordcount-docker-compose
git clone https://github.com/jpalanco/streamparse-wordcount-docker-compose.git
cd streamparse-wordcount-docker-compose
docker-compose scale supervisor=4
docker-compose up -d
You can see how the topology is deployed and counting words in python using the ui at http://127.0.0.1:49080/
Happy hacking!
