 Jose Ramon Palanco
Jose Ramon Palanco 
The world of File Fuzzing is filled with a truly spectacular display of testing. It is the latest shift in software injection and is worth anyone’s attention. But do you really know what File Fuzzing actually is? Let’s get a quick recap.
What is File Fuzzing?
Fuzzing, otherwise known as Fuzz testing is a Black Hat software testing technique consisting in finding implementation bugs by using malformed or semi-malformed data injection in an automated way.

In other terms, it is a quality assurance technique which is used to discover coding errors and security loopholes in software, operating systems and networks and involves inputting massive amounts of random data, called fuzz, to the test subject in an attempt to find its flaws.
File format fuzzing works in a way through which you provide your fuzzed with a legitimate file sample, after which the fuzzer can repeatedly mutate the sample and open it in the target application. If the target application were to crash, something has gone wrong and the mutated file is saved for review at a later time. As the original file never crashes the application, but the mutated one does, it is possible that you have some sort of control over the crash. If you can control what is being written, executed, and read in memory, you can take control over the application flow. If you control the application flow you can make the application do anything, even things it was never supposed to do. That being said, fuzz testing can be seen as an automated software testing technique which involves providing invalid, unexpected, or random data as inputs to a computer program.
This program can, later on, be monitored for exceptions including:
crashes, failing built-in code assertions, memory leaks and so on.
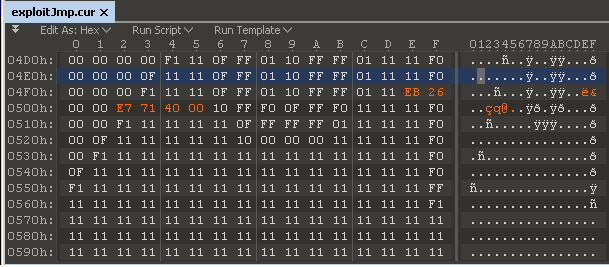
The most common implementation of fuzzers is to test programs that take structured inputs.
The most effective fuzzer usually generates semi-valid inputs that are valid in the way through which they are not directly injected by the parser, but do create unexpected behaviors deeper within the program and are invalid enough to expose corner cases that have not been properly dealt with yet.
An example of file fuzzing:
import fuzzing
seed = "This could be the content of a huge text file."
number_of_fuzzed_variants_to_generate = 10
fuzz_factor = 7
fuzzed_data = fuzzing.fuzz_string(seed, number_of_fuzzed_variants_to_generate, fuzz_factor)
print(fuzzed_data)
Where Fuzzing Originated
Testing programs through the implementation of random inputs can date all the way back to the 1950s when data was stored in punched cards. Programmers would, later on, use these cards that were pulled from the card decks of random numbers as input to computer programs. If an execution revealed some undesired behavior, a bug was detected. This is the earliest and most primitive example of file fuzzing.
The Three Types of Fuzzers
When it comes to file fuzzers, they can be categorized in a few ways.
-
A fuzzer can be generation-based or mutation-based, which highly depends on if the inputs are generated either from scratch or through the modification of existing inputs.
-
A fuzzer can be dumb or smart, which is highly dependent on if it is aware of the input structure or not.
-
A fuzzer can be white, grey, or black-box, which depends on the level of awareness of the program structure.
Use Case Scenarios
One of the best and most common ways through which fuzzing is implemented as an automated technique is during the process of exposing vulnerabilities in security-based programs.
The reason is to prevent these programs from being exploited with malicious intent, and the process of file fuzzing is used to showcase the presence of bugs. This way any bug can be patched and the program will efficiently do what it was meant to do in the first place, provide a higher level of security than ever before. Another way file fuzzing contributes is through exposing bugs.
A fuzzer has to be able to distinguish expected or normal program behavior from unexpected or buggy program behavior.

A machine cannot always distinguish a bug from a feature however, so in automated software testing, this is called the test oracle problem and it is truly fascinating. In order for a fuzzer to distinguish between crashing and non-crashing inputs, it usually looks for the absence of specifications and uses a simple and objective measure.
Crashes are easily identifiable and can indicate potential vulnerabilities such as a denial of service for example. Keep in mind that the absence of a crash does not indicate the absence of a vulnerability. A program written in the C programming language may or may not crash if an input were to cause a buffer overflow.
In this case, the program’s behavior is undefined. In order for a fuzzer to become more sensitive to failures other than crashes, sanitizers can be used.

These can inject assortments that crash the program when a failure is detected. There is a sanitizer for each category of bugs, including ones that detect memory related errors, such as ones that detect undefined behaviors, ones that detect rare conditions and deadlocks, ones that detect memory leaks, ones that detect buffer-overflows, and finally, ones that check for control-flow integrity.
Browser Security is also an extremely popular testing ground that implements fuzzing. Chances are that the browser you are currently using has undergone vigorous fuzzing. The Chromium code used on Google Chrome is continuously fuzzed by the Chrome Security Team which has 15.000 cores at their disposal.
A complete example:
import math
import random
import subprocess
import time
import os.path
from tempfile import mkstemp
from collections import Counter
# Files to use as initial input seed.
file_list = ["./data/pycse.pdf", "./data/PyOPC.pdf", "./data/003_overview.pdf",
"./data/Clean-Code-V2.2.pdf", "./data/GraphDatabases.pdf",
"./data/Intro_to_Linear_Algebra.pdf", "./data/zipser-1988.pdf",
"./data/QR-denkenswert.JPG"]
# List of applications to test.
apps_under_test = ["/Applications/Adobe Reader 9/Adobe Reader.app/Contents/MacOS/AdobeReader",
"/Applications/PDFpen 6.app/Contents/MacOS/PDFpen 6",
"/Applications/Preview.app/Contents/MacOS/Preview",
]
fuzz_factor = 50 # 250
num_tests = 100
# ##### End of configuration #####
def fuzzer():
"""Fuzzing apps."""
stat_counter = Counter()
for cnt in range(num_tests):
file_choice = random.choice(file_list)
app = random.choice(apps_under_test)
app_name = app.split('/')[-1]
file_name = file_choice.split('/')[-1]
buf = bytearray(open(os.path.abspath(file_choice), 'rb').read())
# Charlie Miller's fuzzer code:
num_writes = random.randrange(math.ceil((float(len(buf)) / fuzz_factor))) + 1
for _ in range(num_writes):
r_byte = random.randrange(256)
rn = random.randrange(len(buf))
buf[rn] = r_byte
# end of Charlie Miller's code
fd, fuzz_output = mkstemp()
open(fuzz_output, 'wb').write(buf)
process = subprocess.Popen([app, fuzz_output])
time.sleep(1)
crashed = process.poll()
if crashed:
logger.error("Process crashed ({} <- {})".format(app, file_choice))
stat_counter[(app_name, 'failed')] += 1
else:
process.terminate()
stat_counter[(app_name, 'succeeded')] += 1
return stat_counter
if __name__ == '__main__':
stats = fuzzer()
print(stats)
The Toolchain
A fuzzer can produce a large number of inputs in a short time.
As such, most common fuzzers provide toolchains that automate manual tasks that follow the automated generation of failure-inducing inputs, giving a lot of quality-of-life improvements to the entire process.
As such, there is the automated bug triage, which is used to group a large number of failure-inducing inputs by root cause.
it then prioritizes each individual bug by the level of severity.
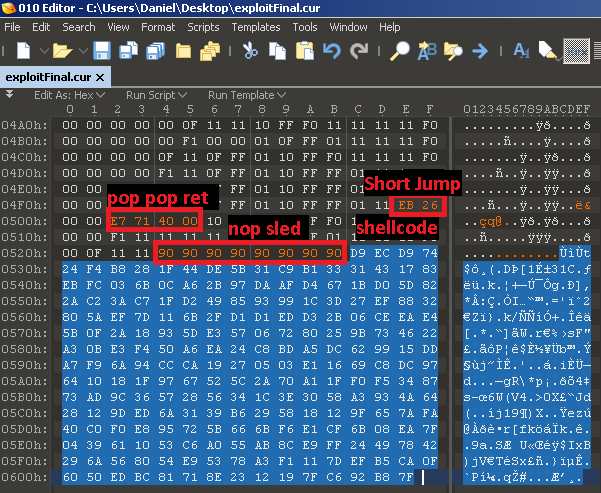
As a fuzzer can produce larger amounts of inputs, many of the failure-inducing ones may effectively expose the same software bug. However, a few of these bugs are security-critical and need to be patched with a higher level of priority.
Another important fact is that the Microsoft Security Research Center otherwise known as MSEC has developed the !exploitable tool which can create a hash for a crashing input that determines its uniqueness and assigns it a rating of exploitable, probably exploitable, probably not exploitable, or unknown.
References
- https://www.blackhat.com/presentations/bh-jp-05/bh-jp-05-sutton-greene.pdf
- https://medium.com/@DanielC7/introduction-to-file-format-fuzzing-exploitation-922143ab2ab3
- https://github.com/secfigo/Awesome-Fuzzing
 The Ultimate Guide to JTAG
The Ultimate Guide to JTAG